One program with multiple in silico tools for approaching complex risk assessments using a weight of evidence approach.
NEW! Bioavailability Prediction
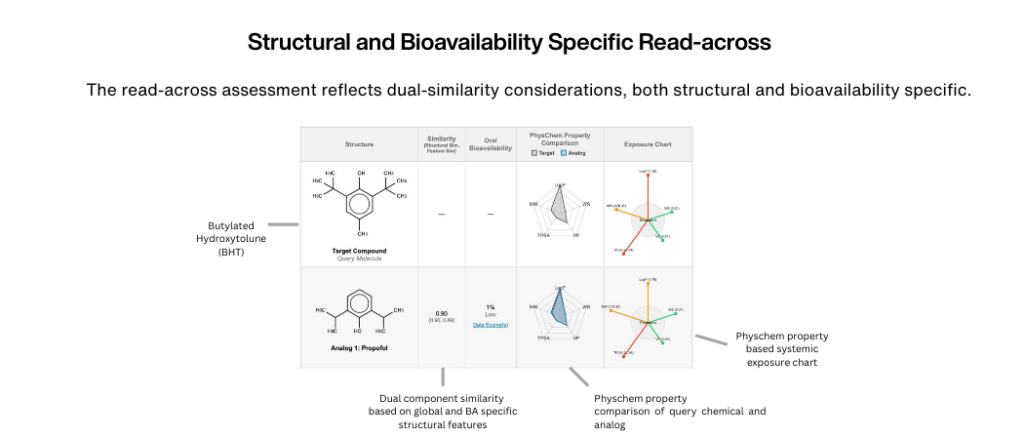
Using a multi-method approach, the QSAR Flex Bioavailability Module estimates the oral bioavailability of trace impurities and extractables and leachables, a key factor in toxicity evaluations for container systems and medical devices.
Curated Databases
Oral Bioavailability Data: 1594 compounds.
Human Liver Microsomal Metabolism (HLM) Data: 4637 compounds.
Values reflect the likelihood that the compound may undergo rapid metabolic degradation, primarily via Phase I oxoreductive pathways involving enzymes such as cytochrome P450s, flavin monooxygenases, esterases, and epoxide hydrolases.
MDR1 (P-gp) Substrate Potential
QSAR Model
Estimates the likelihood that the compound functions as a substrate for key solute carrier (SLC) and ATP-binding cassette (ABC) transporters, factors that shape its intestinal absorption, systemic distribution, and clearance.
CYP Substrate Potential
QSAR Models: CYP3A4, CYP2D6, CYP2C9
Values represent the likelihood that the compound is a substrate for major human cytochrome P450 enzymes.
Formulation Vehicle Effects
Expert Rule-Based
Assesses how different formulation vehicles may influence the compound’s oral bioavailability, based on its physicochemical properties and known formulation behavior patterns.
FlexFilters Methodology
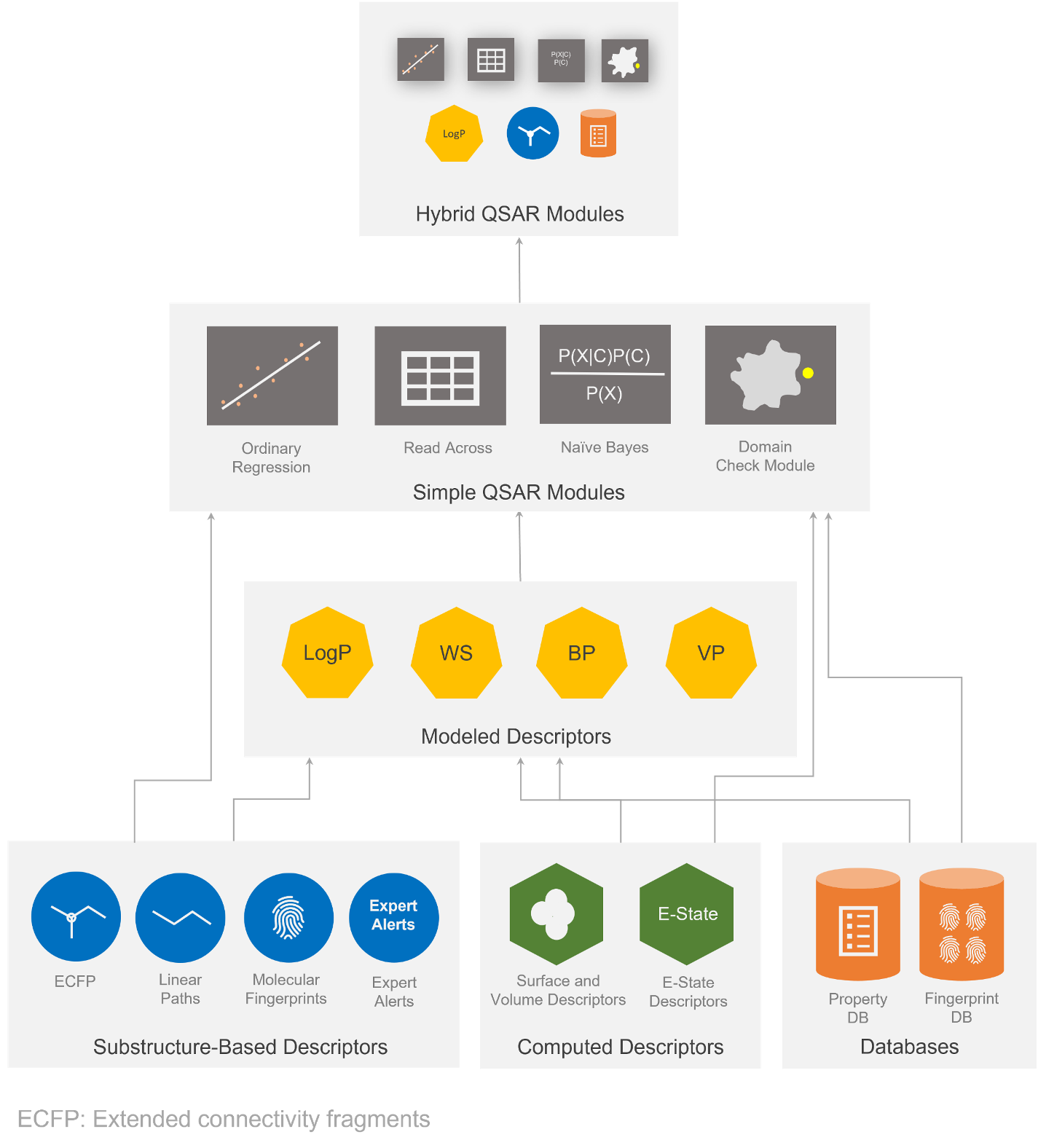
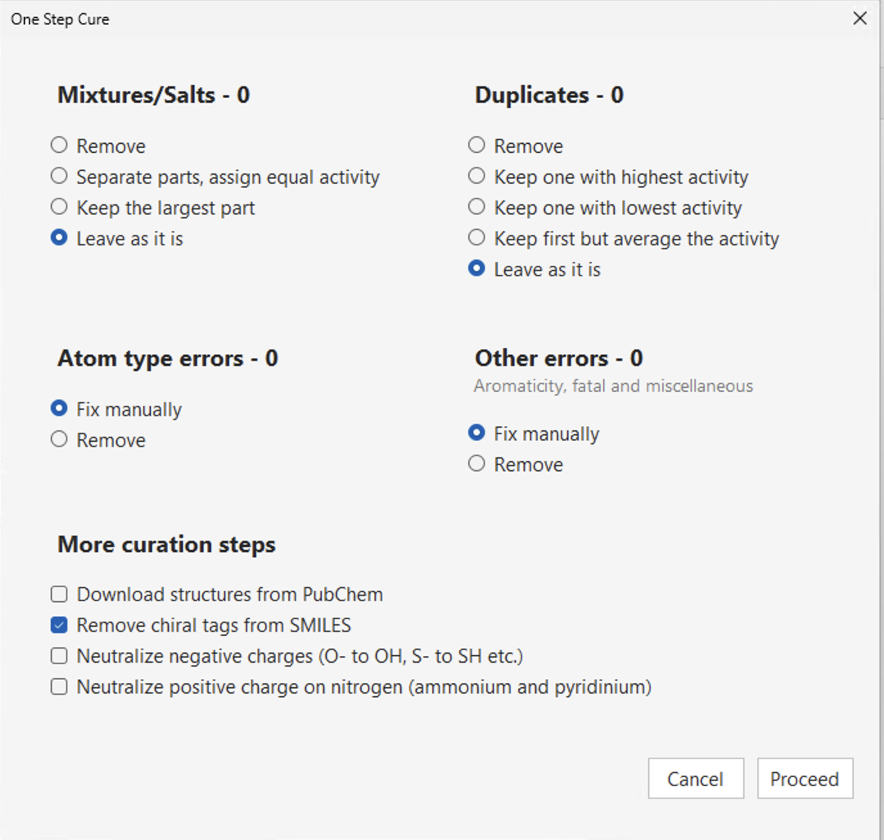
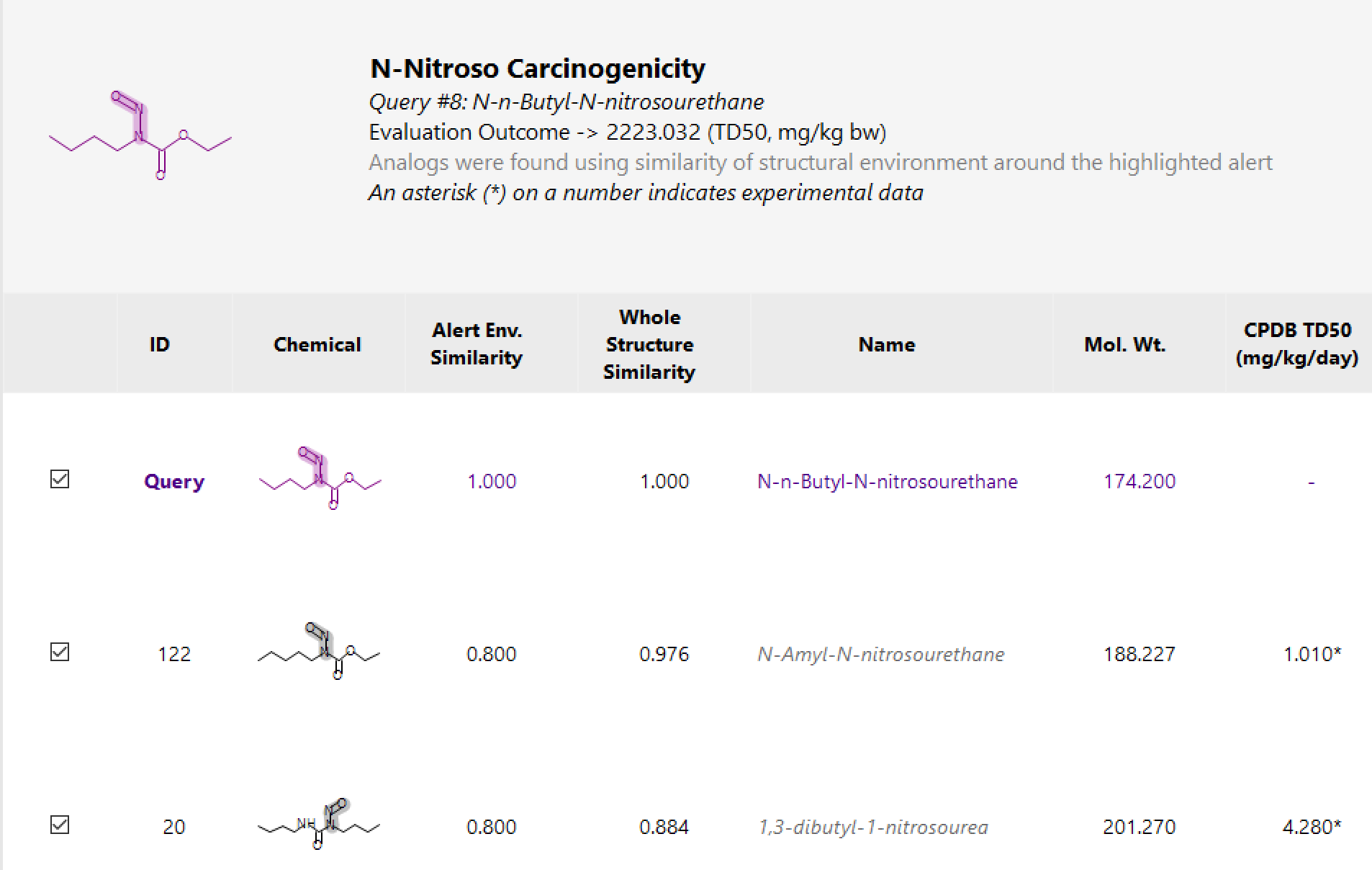
The FlexFilters platform enables the user to execute and integrate various computational toxicology tasks including read-across, molecular fragment handling, descriptor calculations, QSAR modeling, and predictions.
License packages are customized to meet the needs of the user. Factors that affect pricing include length of license, number of endpoints, and number of users. Please contact us to request a quote.